
Autonomic Optimisation
Ian Tree 22 September 2013 12:57:45
Autonomic Optimisation - The Icing on the Cake
I was giving a talk to a groups of developers on some aspects of autonomic optimisation last week. I had asked the group to bring along some sample problems that we could use to explore the potential for some of the techniques that we were discussing. Unfortunately the very first of the problems that was offered proved so compelling that most of the talk was taken up discussing aspects of multi-threaded application design that we were left with 10 minutes at the end of the talk to consider how to apply autonomic optimisation techniques to the problem. Although somewhat disappointed that I had allowed us to get side-tracked to such an extent the group was generally very happy with session as it had brought into stark relief one fundamental point about application optimisation, autonomic or otherwise; the point being that optimisation is a layer that can only be applied over the top of a good design.
"We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil"
The quote is attributed to Donald Knuth, who is quoted as saying that he heard it from Tony (C.A.R) Hoare, who denies ever having said it!
The Problem
The problem was a snippet from a reply to a post in some programming forum.
| "One (annoying) thing I found was there seems to be a hard-coded limit on the number of threads a process can have: 2000. It's a problem for me because I was, err, port-scanning a network at the time, and my code launched a thread for every IP address, then launched a thread for every port (for every IP address). I needed some code to sit there and check if the thread was actually created. If it wasn't, I would delay 100ms and try again, until all my threads were launched." |
There was a cacophony of "OMG", "WTF", "that'll never work" and similar. I liked the problem because it is well bounded and the details of the problem do not obscure the multi-threading aspects that need to be addressed to come to an efficient implementation. Clearly the author of the post had got his solution to work, I suspect though that a good single threaded design would manage to pip his multi-threaded implementation to the performance post.
There are no "absolute" rules of multi-threaded application design but any experienced application developer can see that the solution offered by the author is a triumph of "Brute Force and Ignorance" over good design. It would be my guess that the author is an inexperienced developer who has discovered the joys of threads but has not been exposed to different models for using them and has definitely not acquired the skills necessary for good multi-threaded application design. We won't dwell on the shortcomings of the offered solution, merely nothing that :-
More threads does NOT equate to more throughput.
The cost of setting up and tearing down a thread will dominate the workload of the application.
Restating The Problem
I will just tidy up the problem statement a little to allow us to explore a concrete design for the application.
| Given a file network addresses (in CIDR format) the application must check every host within the network address range and determine which ports from a fixed list (100 ports) the host is listening on. For each port that is open the application should write a line in the log file containing the IP address, Host Name and port number. The application should complete processing of the input file in the shortest possible time. |
A Design
In the group discussion that followed we explored a number of design patterns and options, I have trimmed that discussion down to focus on what we collectively decided on as the reference, the discussion was slightly skewed towards a design that would allow us to look at the possibility of adding autonomic optimisation.
Understanding the Workload
We began by deriving a a model for the workload of the application. Factorising the workload gives us the following picture.
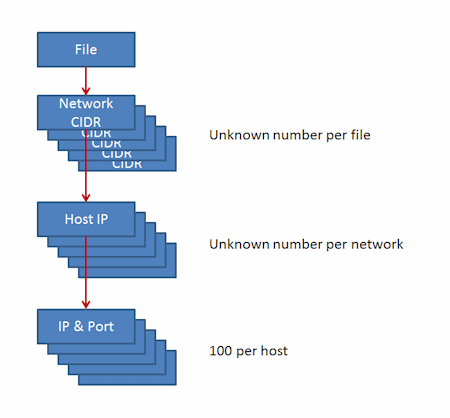 |
Understanding the Processing Flow
The processing flow and boundaries are clear.
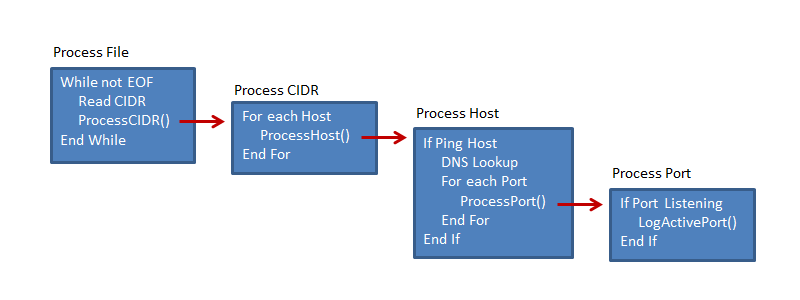 |
Identifying the MUX & DEMUX Points
The calls to ProcessCIDR(), ProcessHost() and ProcessPort() can all be multiplexed. Calls to LogActivePort() must be demultiplexed (serialised).
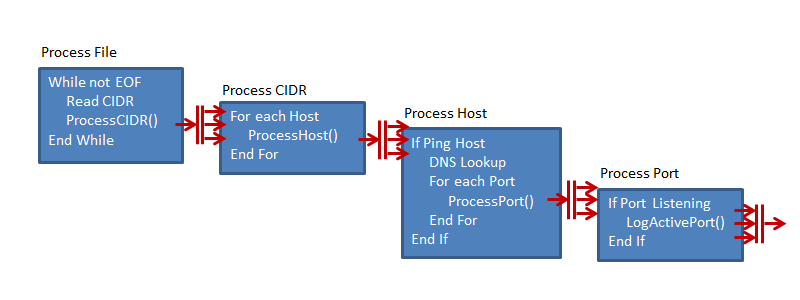 |
Selecting the Threading Model and Processing Affinity
Calls to ProcessCIDR()
As the processing workload in the ProcessCIDR() unit is light we will use a group of persistent threads that will each process multiple ProcessCIDR() calls, therefore we will need a message passing interface and intermediate queue. The queue is of fixed size and will block calls to pass a new message if the queue is full.
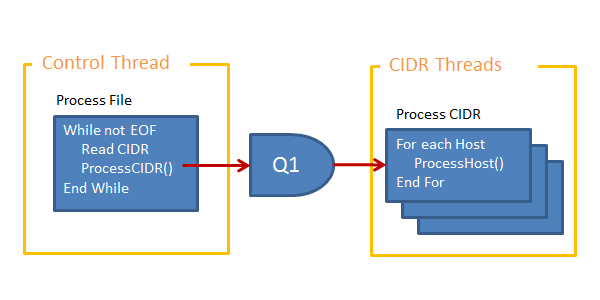 |
Calls to ProcessHost()
As the processing workload in the ProcessHost() unit is light we will use a group of persistent threads that will each process multiple ProcessHost() calls, therefore we will need a message passing interface and intermediate queue. The queue is of fixed size and will block calls to pass a new message if the queue is full.
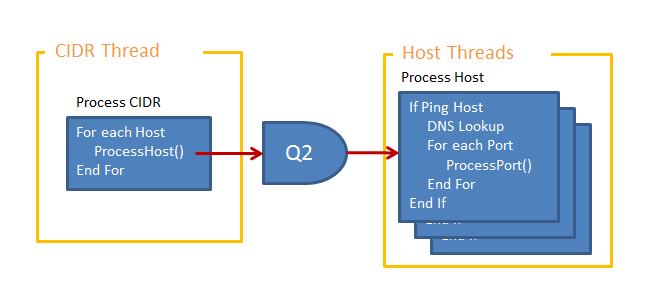 |
Calls to ProcessPort()
As the processing workload in the ProcessPort() unit is light we will use a group of persistent threads that will each process multiple ProcessPort() calls, therefore we will need a message passing interface and intermediate queue. The queue is of fixed size and will block calls to pass a new message if the queue is full.
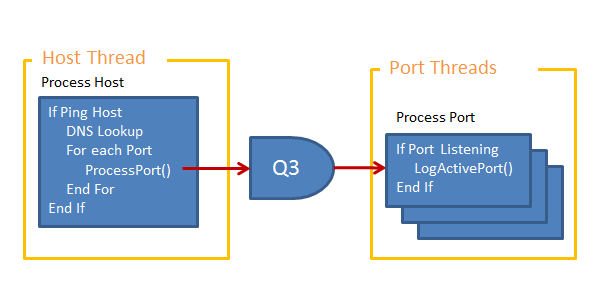 |
Calls to LogActivePort()
Writing to the log is a serialised process therefore we will have a single persistent thread driven from a queue.
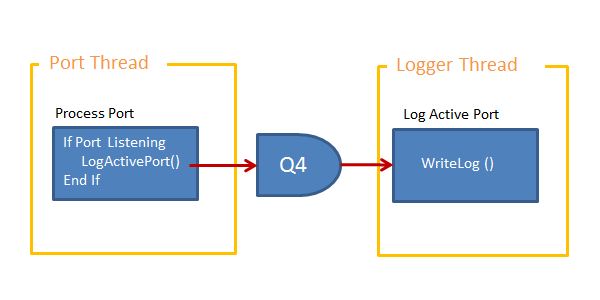 |
Collapsing Threads into a Threadpool
The CIDR threads, the Host threads and the Port threads can be collapsed into a single threadpool, all threads in the pool are capable of processing all three types of message. Using the threadpool will cause the queues Q1, Q2 and Q3 to be consolidated into a single queue, this single queue will have to be a priority queue with CIDR thread messages assigned the lowest priority, Host thread messages assigned a medium priority and Port thread messages assigned the highest priority. If you cannot see why the queue needs to be a priority queue then do the thought experiment of inverting the priority of the messages and bear in mind that the queue has fixed capacity and blocks on calls to post messages to the queue when it is full.
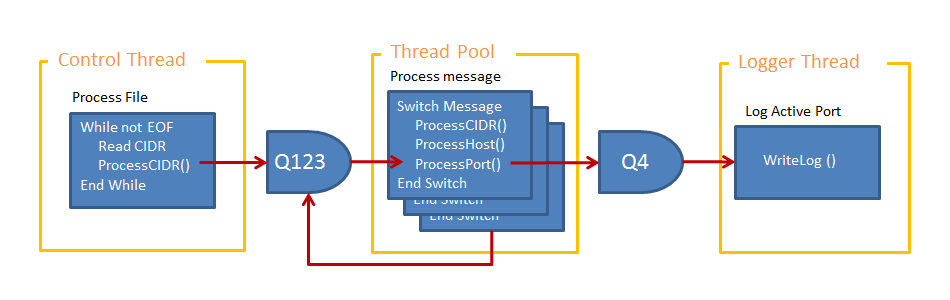 |
Thread Containment and Control
All of the threadpool threads and the Logger thread are contained by the Control thread, it will initiate them and be responsible for signalling the threads to shut down.
The control thread will initialise the queues and initiate all of the threads it will read the input file creating a CIDR message for each record and post the message to the Q123 queue. Once all of the CIDR records have been processed the Control thread should monitor the Q123 queue and the threadpool waiting until the queue is empty and all threads in the threadpool are in the "Idle" state i.e. polling the queue for new messages. Once the Q123 has drained and the threadpool members are all idle then the Control thread should signal the threads in the threadpool to shut down. The Control thread then monitors the Q4 queue and the Logger thread, once the Q4 queue is drained and the Logger thread is idle then it should signal the Logger thread to shut down. Once all of the threads have completed termination the Control thread can terminate.
Message Priority Quotas in the Priority Queue
The priority queue mechanism used for "Q123" should be capable of applying capacity quotas to the different priority bands. 10% of the capacity should be allocated for the low priority (CIDR) messages, 20% should be allocated to the medium priority (Host) messages and the remaining 70% allocated to the high priority (Port) messages. This mechanism will only allow low priority messages to occupy 10% of the capacity of the queue, it will only allow low and medium priority messages to occupy 30% (10% + 20%) of the capacity of the queue. High priority messages can occupy whatever capacity is available in the queue. If a quota is exhausted then the queue posting mechanism will block until the quota constraint is relieved.
Autonomic Optimisation
We add an "Autonomic Optimiser" component to the application design this component is capable of monitoring states and rates in the other components of the application and changing the setting of a number of controls that affect the throughput of the application.
What Controls are available to the Autonomic Optimiser?
The number of active threads in the threadpool.
The capacity of Q123.
The Priority Quota levels on Q123.
The capacity of Q4.
What Metrics should the Autonomic Optimiser Monitor?
Throughput
At first glance it may appear that measuring the rate of message posting onto Q4 would provide us as with a reasonable measure of throughput for the application. However, on closer inspection we observe that the "null" result from processing a "processPort" message for a port that is not listening is as important an output as the outcome for a listening port, therefore this would indicate that the rate of throughput would be better measured as the rate of dequeues of "processPort" messages. A look back at the workload factorisation shows that the processPort processing represents the predominant workload of the application.
Queue Behaviour
There are many metrics that we could record to enable us to investigate the behaviour of the queues in the application, to keep things simple we will restrict ourselves to the following.
Per unit time, the number of calls to post a message that blocked because the queue was full.
Per unit time, the number of calls to post a message that blocked because the Priority Quota was exceeded.
Per unit time, the number of calls to poll for a message that returned nothing because the queue was empty.
Autonomic Optimisation Strategy
Clearly the "biggest knob" on the optimiser dashboard is the one that controls the number of active threads in the threadpool. The optimiser should, at regular intervals, inspect the recent history of throughput achievement if the throughput has been increasing then it should add another thread to the threadpool. If the throughput achievement is constant of decreasing then the optimiser should look at the recent history of queue behaviour to determine if there is evidence of "queue exhaustion" constraining the throughput, if this is the case then the optimiser should increase the capacity (or Quota allocation) of the queue in question. If there is no evidence of queue behaviour constraining the throughput achievement then the optimiser should decrease the number of threads in the threadpool by one.
Post Script
I will be restarting the session with the same group of developers next month and, providing we don't get side-tracked again. I will post a summary of that session after it happens.
Share: | Tweet |
- Comments [0]
