
Are GIF Images Really Limited To 256 Colours?
Ian Tree 02 December 2015 21:16:26 - Amsterdam
There has been quite some debate on this topic over the years, much of it peppered with misunderstanding, misinformation and downright netbollox. In this article we take a fresh look at the question from the point of view of the words and intentions of the GIF specifications and the conformance of implementations in different codecs.Specifications
There are two different versions of the GIF specification, the first identified as “87a” was issued in 1987 and this was followed by the “89a” version in 1989.
The 1987 specification describes two key features that have an impact on the maximum colours question. First an image file or stream may contain multiple separate images and secondly each image can specify a separate colour map. Appendix D of the specification makes it clear how codecs are expected to implement a stream that is encoded with separate images.
| "Since a GIF data stream can contain multiple images, it is necessary to describe processing and display of such a file. Because the image descriptor allows for placement of the image within the logical screen, it is possible to define a sequence of images that may each be a partial screen, but in total fill the entire screen. The guidelines for handling the multiple image situation are: 1. There is no pause between images. Each is processed immediately as seen by the decoder. 2. Each image explicitly overwrites any image already on the screen inside of its window. The only screen clears are at the beginning and end of the GIF image process. See discussion on the GIF terminator.” |
It is clear that the specification supports composite images both through tiling and through overlaying. Given that each image (or tile) supports a separate colour map each containing up to 256 individual colours it is clear that even in the 87a specification images with more than 256 colours are supported, providing that the colour distribution in the image is such that it can be broken down into sub-images (or tiles) with each tile limited to 256 colours. In theory any image with any number of colours can be decomposed into tiles or overlays (or a combination of both) using sub-images as small as a single pixel, however, such an implementation may not be realistic.
It must now be stated that extending the colour palette of an image through the use of composite tiles or overlays was not foreseen at the time of writing the specification. The part of the specification that describes the use of Local (per image) colour maps states the following.
| “A Local Color Map is optional and defined here for future use.” |
The 89a specification, published in 1989 was intended to extend the original 87a specification as can be seen from the foreword of that document.
| “This document defines the Graphics Interchange Format(sm). The specification given here defines version 89a, which is an extension of version 87a.” |
Although the text of the “Appendix D” from the 87a specification does not appear in the 89a version, there is no text that negates the continued validity and applicability of the appendix. Multiple (sub) images in a single GIF stream or file are still recognized as can be seen from the section defining the “Image Descriptor” block.
| “Exactly one Image Descriptor must be present per image in the Data Stream. An unlimited number of images may be present per Data Stream.” |
The 89a specification introduced the (per image) Graphics Control Extension (GCE); a generic mechanism for implementing an extension was defined in the 87a specification.
| “The Graphic Control Extension contains parameters used when processing a graphic rendering block. The scope of this extension is the first graphic rendering block to follow. The extension contains only one data sub-block. This block is OPTIONAL; at most one Graphic Control Extension may precede a graphic rendering block. This is the only limit to the number of Graphic Control Extensions that may be contained in a Data Stream.” |
It should be noted that although the GCE block is optional the “Version Number” section of the 89a specification states the following.
| “The encoder should make every attempt to use the earliest version number covering all the blocks in the Data Stream; the unnecessary use of later version numbers will hinder processing by some decoders.” |
The GCE introduced three new fields all of which are relevant to the discussion about the number of colours limitation in GIF images. The first field is the “Delay Time” which is described as follows.
| “Delay Time - If not 0, this field specifies the number of hundredths (1/100) of a second to wait before continuing with the processing of the Data Stream. The clock starts ticking immediately after the graphic is rendered.” |
The delay time field allows a stream containing multiple images to be rendered as an animation. There is a clear implication that a value of zero for the field would elicit the behaviour described in Appendix D of the 87a specification, rendering the next image in the stream immediately after the current one has been rendered.
The second field is a packed field of which 3 bits are used to describe the disposition of the image which is described as follows.
| “Disposal Method - Indicates the way in which the graphic is to be treated after being displayed. Values : 0 - No disposal specified. The decoder is not required to take any action. 1 - Do not dispose. The graphic is to be left in place. 2 - Restore to background color. The area used by the graphic must be restored to the background color. 3 - Restore to previous. The decoder is required to restore the area overwritten by the graphic with what was there prior to rendering the graphic. 4-7 - To be defined.” |
The value of 1 “Do not dispose” follows the processing described in Appendix D of the 87a specification.
The last new field of interest is the “Transparency Index” and the corresponding flag in the packed fields, described as follows.
| “Transparency Index - The Transparency Index is such that when encountered, the corresponding pixel of the display device is not modified and processing goes on to the next pixel. The index is present if and only if the Transparency Flag is set to 1.” |
It may not be immediately obvious how this field relates to the maximum colours question. Allowing a transparent colour to be used in an image removes any restriction on colours and their distribution, any image with any number of colours can be decomposed into a series of overlaid images using a transparent colour in all but the first image.
In conclusion the GIF specifications do and always have supported mechanisms that allow for encoding images with an unlimited number of colours.
Implementations
This section looks at the implementation of the specification in a few illustrative codecs to see if they constrain the maximum number of colours in practical use.
GIF 87a Tiled Image Behaviour
A GIF image was prepared with 200 (20 x 10) images, each image 20 x 20 pixels tiling a 400 x 200 logical screen. Each tile uses a different colour index in a Global Colour Map. The image is marked with a version identifier of “87a”. The image is then viewed in different software applications to see how their respective codecs perform.
MS Edge and MS IE 11 both only display the first image out of 200, interestingly MS Paint displays the complete 200 tile image. Google Chrome (on Windows 10) displays the complete 200 tile image, however, it treats the image stream as an animation and enforces a default minimum delay time on each image in the stream taking approximately 20 seconds to render the complete image (10/100ths sec delay time). Mozilla Firefox displays the complete 200 tile image without any rendering delays.
Of the codecs tested only Mozilla Firefox conforms to Appendix D of the 87a specification.
 GIF 87a Image - 200 Tiles |
GIF 89a Tiled Image Behaviour
A GIF image was prepared with 200 (20 x 10) images, each image 20 x 20 pixels tiling a 400 x 200 logical screen. Each tile uses a different colour index in a Global Colour Map and specifies a delay time of 0 in the GCE. The image is marked with a version identifier of “89a”. The image is then viewed in different software applications to see how their respective codecs perform.
MS Edge, MS IE 11 and Google Chrome all display the complete 200 tile image as an animation with an enforced delay on each image. All three codecs took about 20 seconds to render the complete animation, implying a default delay time of 10/100ths seconds per image. Mozilla Firefox displays the complete 200 tile image without any rendering delays.
Again only the Mozilla Firefox codec conformed to the expectation that a zero delay time in a GCE would induce the behaviour as laid out in Appendix D of the 87a specification.
 GIF 89a Image - 200 Tiles |
GIF89a Tiled Animation
A GIF 89a Image was prepared identical to that used in the previous experiment, except that the delay time set in each GCE was set to 20 (20/100ths of a second). The image is then viewed in different software applications to see how their respective codecs perform.
All four codecs displayed the complete 200 tile image, taking 40 seconds to complete the rendering process. All codecs conform to the behaviour expected from the 89a specification.
 GIF 89a Animation - 200 Tiles |
GIF 89a Tiled 512 Colour Image Behaviour
A GIF 89a Image was prepared with two side-by-side images (tiles), each tile was populated with a 16 x 16 grid of squares, each square 20 x 20 pixels of a different colour, thus the complete image should render 512 different colours. One tile used a Global Colour Map and the other a Local Colour Map. Both images had a GCE with a delay time set to zero. The image is then viewed in different software applications to see how their respective codecs perform.
MS Edge, MS IE 11 and Google Chrome all display the complete image with all 512 colours, there was no perceptible delay visible during rendering. From the previous examples these three codes will have treated the image as an animation and would have enforced a 10/100ths of a second delay between the first and second tile but this delay would not be visible during rendering. Mozilla Firefox rendered the image correctly with delay in the rendering.
The behaviour of all codecs was as would be expected from the previous experiments.
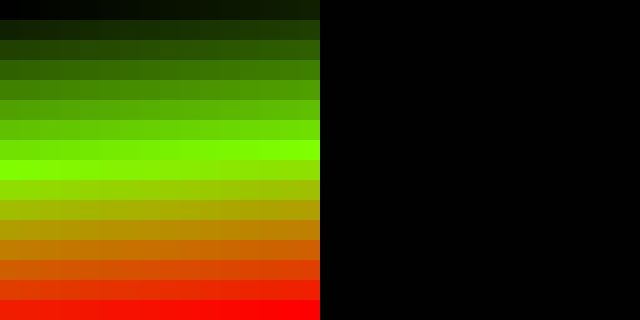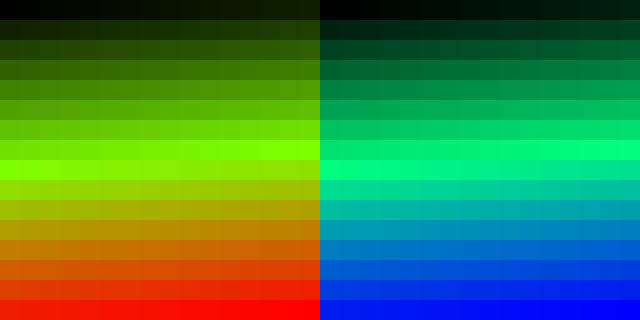 GIF 89a Image - 512 colours |
Off Topic
The GIF 89a specification introduced the Application Extension which provided a mechanism for individual application to store additional persistent information in the GIF image stream. This extension mechanism was used by Netscape to add a field that controls how many times the render mechanism will “play” an animation. This extension is recognised by all of the codecs in common use and all agree that a value of zero for the field means that the animation should be played continuously until the image is dismissed. They also agree that if the extension is not present then the animation is played only once. They do not agree on the meaning of the field when the value is non-zero, with some using the field value as an iteration counter for the render loop where a value of one causes the animation to be played once while others take it as a repeat counter where a value of one causes the animation to be played once and repeated once, therefore played twice. Unfortunately documentation is unclear on which interpretation is correct, both are equally valid. It should be noted that most common use is to play once or play continuously therefore omitting the extension to play once and setting a count of zero to play continuously will work in most codecs.
Conclusion
In theory a GIF image can support an unlimited (or rather limited only by the supported colour encoding which is 24 bit RGB - RGB888) number of colours. However, the implementation in a number of codecs that are in common use does put practical limits on the number of different colours that can be displayed, this limit is however far in excess of 256. The rendering time for a GIF image stream that contains multiple images as tiles or overlays is entirely dictated by the minimum default image delay time set by non-conforming codecs. The delay time imposed by all of the non-conforming codecs that were examined is 10/100ths of a second. It is therefore possible to budget for that delay and set a maximum number of colours that can be used in practice accordingly. If a total render time of three seconds is considered to be acceptable then this would allow for 30 separate images in the stream this would permit 30 * 255 = 7,650 different colours to be comfortably displayed in an image.
MS Edge and MS IE 11 are considered non-conforming to the GIF 87a specification as they do not recognize multiple images in a single image stream. Google Chrome is considered non-conforming to the GIF 87a specification as it does not follow Appendix D and treats the multiple in-stream images as an animation and imposes a minimum image delay time. Mozilla Firefox is considered as conforming to the GIF 87a specification.
MS Edge, MS IE 11 and Google Chrome are all considered as non-conforming to the GIF 89a specification as they all impose a minimum image delay time for in-stream images that have a delay time of zero specified in the Graphics Control Extension block. The Mozilla Firefox codec is considered as conforming.
It must be said that given the stricter conformance of the Mozilla Firefox codec, in the areas considered, they would also get my vote for the most logical implementation of the Netscape Application Extension iteration count.
Share: | Tweet |
- Comments [0]
 Background
Background DX Common Code
DX Common Code DX Application Design Guide
DX Application Design Guide Heavy Lift Computing
Heavy Lift Computing
